
RöKo Digital 2024 – Das moderne KI-Modell ist universell und multitaskingfähig

KI-Modelle mit breitem Grundlagenwissen und Möglichkeiten zur Spezialisierung – so genannte Foundation Models – machen auch maschinelle Befundungen für Erkrankungen möglich, für die es eigentlich nicht genügend KI-Trainingsdaten gibt.
-
Präsentationstag:18.05.2024 1 Kommentare
-
Autor:biho/ktg
-
Sprecher:Fabian Kießling, RWTH Aachen
-
Quelle:RöKo 2024
Üblicherweise läuft es so: Ein KI-Model soll eine ganz spezifische Aufgabe erfüllen und erhält zum Training möglichst viele und hochwertige Trainingsdaten. Die Trainingsdaten bilden die Grundlage der KI-Funktionalität, den so genannten Ground Truth. In der Radiologie stehen die notwendigen Trainingsdaten häufig nicht in ausreichender Menge zur Verfügung – beispielsweise bei seltenen Erkrankungen – oder sind zu unsauber, um eine KI erfolgreich zu trainieren.
Foundation Models lernen wie Kinder
Fabian Kießling, RWTH Aachen, wählte eine neuere Trainingsmethode: Er und sein Team trainierten ein Foundation Model. Ein solches „Grundlagenmodell“ wird auf großen Mengen ganz verschiedener Daten vortrainiert und anschließend für eine Vielzahl von spezifischen Aufgaben angepasst oder weiter trainiert. Für diese Spezialisierung benötigt man dann nur noch wenige Daten. „Der Algorithmus lernt wie ein Kind anhand von Beispielen und ist dabei gleichzeitig mehreren Eindrücken ausgesetzt. Das Kind lernt parallel, was ein Haus, ein Mensch, ein Hund, das Knie von einem Hund und das Knie von einem Menschen ist“, erläuterte Kießling. „Auf dieser breiten Grundlage kann es sich später spezialisieren und unterscheiden, was eine Kniearthrose und was eine Kniearthritis ist.“
Trainingsdaten: Nicht zu sauber, nicht zu detailverliebt
Das Team um Kießling wählte für ihr Foundation Model unter anderem 2D-Röntgenthoraxbilder, 3D-MRT-Hirnbilder und histologische Schnittbilder. Das KI-Modell lernte auch von segmentierten und klassifizierten Bildern. Die Datensätze wurden zusätzlich mit verschiedenen Filtern oder Rauschen belegt. So lernte das KI-Modell, auch unsaubere Bilder auszuwerten. Denn: Sind die vortrainierten Daten nicht repräsentativ für die Praxis, leidet später die Zuverlässigkeit. Oder analog: Sieht das Kind nur Einfamilienhäuser, erkennt es unter Umständen später nicht, dass ein Hochhaus auch ein Haus ist.
Zu spezialisiert dürfen die Daten für das Vortraining aber auch nicht sein: „Dann kann der Algorithmus nicht mehr abstrahieren und wird ungenau“, so Kießling. Das nennt man Catastrophic Forgetting. Anschaulicher betrachtet: Bevor zwischen Kniearthrose und Kniearthritis unterschieden werden kann, braucht es viele verschiedene Knieansichten.
Spezialisierung: Wenige, aber hochwertige Daten
Für die Spezialisierung auf verschiedene Aufgaben wählten die Forscher:innen gut annotierte und qualitativ hochwertige Daten (beispielsweise: Kniearthrose und Kniearthritis). Im Vergleich brauchten sie aber viel weniger Daten als für das Training üblicher KI-Modelle. Im Test zeigte sich: „Zum Erkennen einer Pneumonie benötigte unser Foundation Model nur zehn Prozent der Datenmengen, als für das Training eines üblichen KI-Modells notwendig gewesen wären“, so Kießling.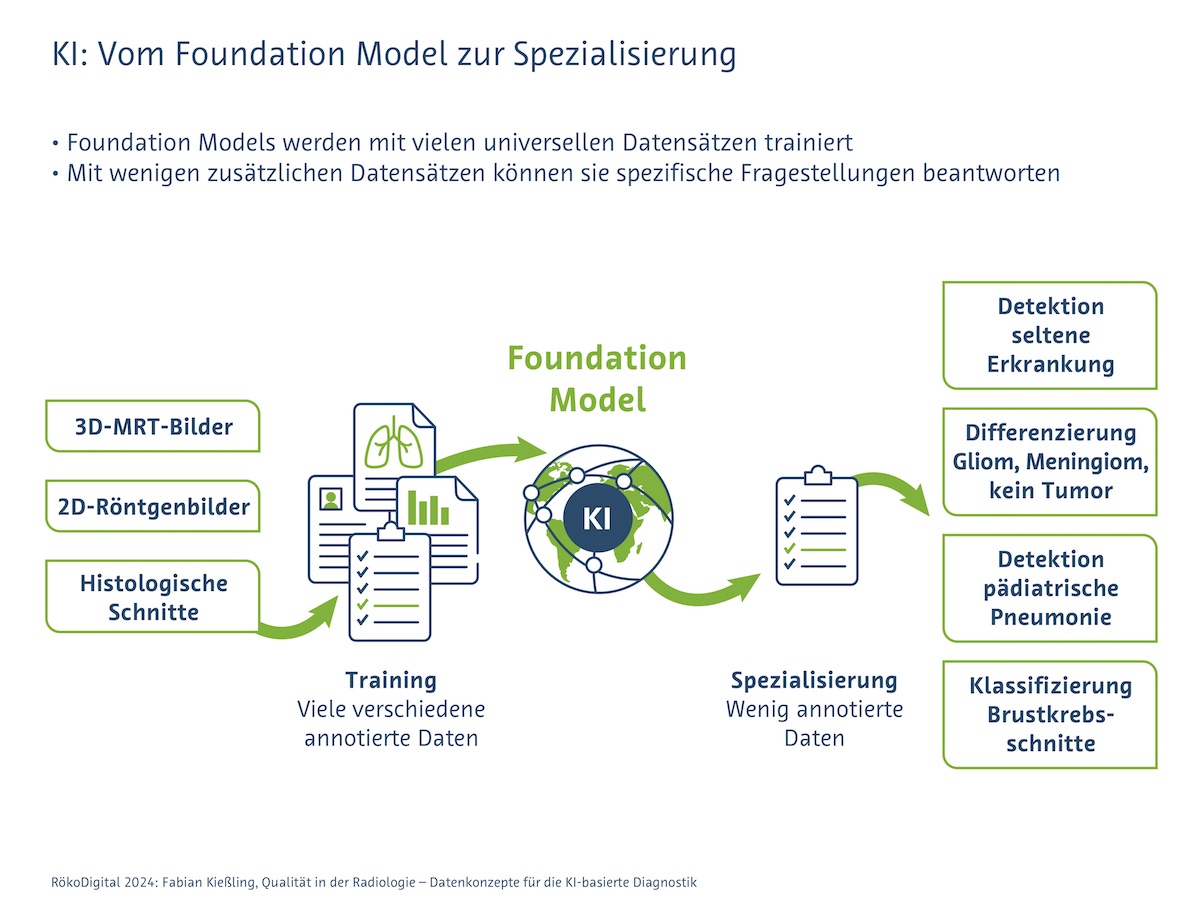
Trainingsdaten: Virtuell mit Generative Adversial Networks (GAN)
Eine andere Möglichkeit, Daten für ein KI-Modell zu gewinnen, funktioniert mit einem zweiten KI-Modell. Der erste Algorithmus lernt, aus echten Daten virtuelle Daten zu schaffen, die ein neues Set an Bildern. Ein zweiter Algorithmus, ein Diskriminator, soll dann die echten von den virtuellen Daten unterscheiden. Wenn der Diskriminator keinen Unterschied mehr zwischen den echten und den virtuellen Daten wahrnehmen kann, können auch Radiolog:innen nicht mehr unterscheiden, was echt und was artifiziell ist. So kann das KI-Modell kann beispielsweise einen normalen Röntgenthoraxbefund generieren und diesen schrittweise so verändern, dass er pathologisch wird. „Mit Hilfe einer solchen KI können Sie dem System auch virtuelle Datensätze hinzufügen, die Sie bis dato noch gar nicht in Ihrer Datenbank hatten und damit neue Krankheitsentitäten aufnehmen“, so Kießling.
Fazit
Für ein gut arbeitendes Foundation Model sind viele und vielfältige Daten der Schlüssel zum Erfolg. Die Trainingsdaten können auch virtuell erstellt werden. Für die nachfolgende Spezialisierung des KI-Modells sind saubere und detaillierte annotierte Datensätze notwendig. Man benötigt jedoch sehr viel weniger Daten als für andere KI-Modelle üblich – und kann das Foundation Model daher auch auf sehr spezielle Aufgaben trainieren.

